ConSinger: Efficient High-Fidelity Singing Voice Generation With Minimal Steps
Abstract
Singing voice synthesis (SVS) system is expected to generate high-fidelity singing voice from given music scores (lyrics, duration and pitch). Recently, diffusion models have performed well in this field. However, sacrificing inference speed to exchange with high-quality sample generation limits its application scenarios. In order to obtain high quality synthetic singing voice more efficiently, we propose a singing voice synthesis method based on the consistency model, ConSinger, to achieve high-fidelity singing voice synthesis with minimal steps. The model is trained by applying consistency constraint and the generation quality is greatly improved at the expense of a small amount of inference speed. Our experiments show that ConSinger is highly competitive with the baseline model in terms of generation speed and quality.
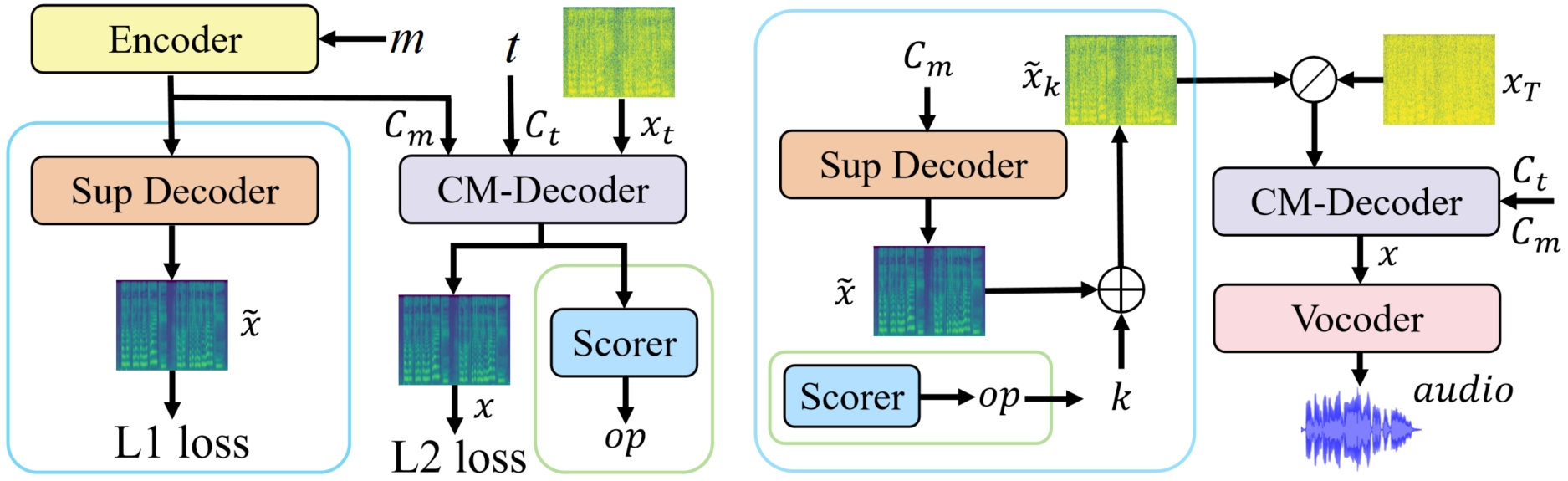
Singing voice synthesis
The below audio samples show the comparison between ground-truth (GT), GT(mel + HiFiGAN), FFTSinger, DiffSinger, ConSinger(v3). Samples are selected from the test dataset of PopCS.
Sample 1: 倘若我心中的山水,你眼中都看到,我便一步一莲花祈祷
| GT | GT (mel + HiFiGAN) | FFTSinger (NFE:1+0, RTF:0.0166) |
|---|---|---|
| DiffSinger (NFE:1+51, RTF:0.0516) |
ConSinger (NFE:1+1, RTF:0.0188) |
|---|---|
Sample 2: 怎知那浮生一片草,岁月催人老,风月花鸟一笑尘缘了
| GT | GT (mel + HiFiGAN) | FFTSinger (NFE:1+0, RTF:0.0166) |
|---|---|---|
| DiffSinger (NFE:1+51, RTF:0.0516) |
ConSinger (NFE:1+1, RTF:0.0188) |
|---|---|
Sample 3: 没办法好可怕,那个我不像话,一直奋不顾身
| GT | GT (mel + HiFiGAN) | FFTSinger (NFE:1+0, RTF:0.0166) |
|---|---|---|
| DiffSinger (NFE:1+51, RTF:0.0516) |
ConSinger (NFE:1+1, RTF:0.0188) |
|---|---|
Sample 4: 抱一抱,就当作从没有在一起,好不好,要解释都已经来不及
| GT | GT (mel + HiFiGAN) | FFTSinger (NFE:1+0, RTF:0.0166) |
|---|---|---|
| DiffSinger (NFE:1+51, RTF:0.0516) |
ConSinger (NFE:1+1, RTF:0.0188) |
|---|---|
Ablation Studies
The final version of ConSinger was inspired by an ablation experiment. When performing ablation experiments, we found that the result quality restored by ConSinger(v2) is not simply linear with the level of noise.
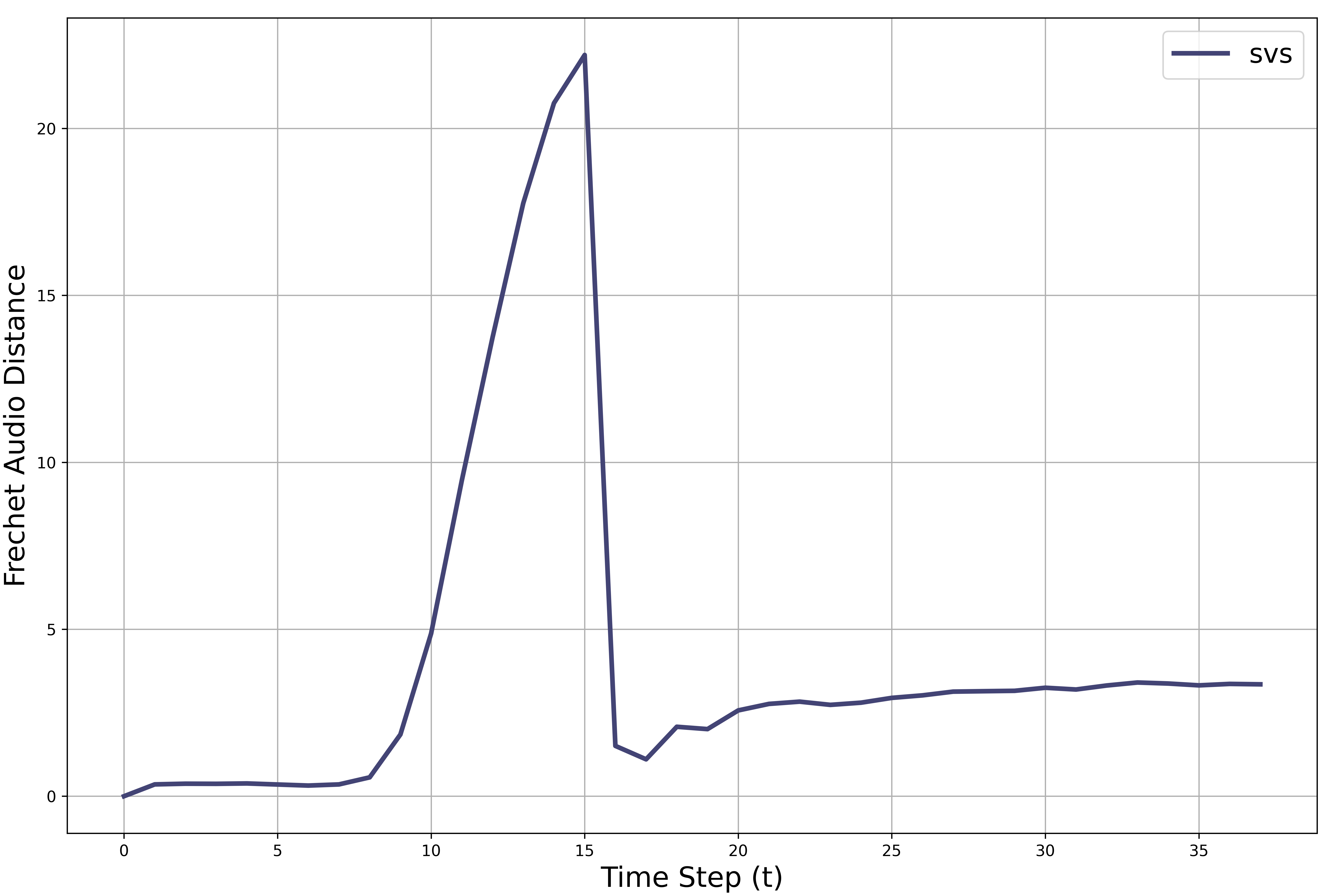
Therefore, we design a scorer that stores the current optimal restore point on the probabilistic flow trajectory during training.
Same as DiffSinger, ConSinger (v2 & v3) denoise prior knowledge with noise to get better results. That is, the supplementary decoder provides the mel-spectrogram skeleton for the model, the addition of a small amount of noise on this basis helps the denoiser to perform a more elaborate carving. Our experimental results show that DiffSinger does not fully exploit the performance of the network by predicting and denoising a small amount of noise at a time, and therefore it consumes abundant inference time. Please refer to the paper for more technical details and explanations.